
澳门新莆京游戏app官方版客户端
百万最新免费软件游戏
下载


新智元报道
【新智元导读】外媒SemiAnalysis的突围一篇深度长文,全面分析了DeepSeek背后的奥秘秘密——不是‘副业’项目、实际投入的曝光训练成本远超600万美金、150多位高校人才千万年薪,让全攻克MLA直接让推理成本暴降......
DeepSeek这波强攻,世界彻底把OpenAI逼急了——深夜紧急上线o3-mini。抄作才集出千
整整半个月,业天中国AI承包了国内外各大头条,结开影响力只增不减。突围
关于DeepSeek模型训练数据、奥秘GPU用量、曝光成员构成、让全RL训练算法,世界早已成为所有人的抄作才集出千关注焦点。
SemiAnalysis一篇深度报道中,业天从多个方面进行了推测——训练成本、对闭源模型利润影响、团队等等。

其中一些关键亮点包括:
DeepSeek不是‘副业’,在GPU等硬件支出远超5亿美元,论文中600万美元仅是预训练运行GPU成本,研发、硬件总拥有成本(TCO)被排除在外
DeepSeek大约有5万块Hopper GPU,包括特供版H800和H20
DeepSeek大约有150名员工,并定期从北大、浙大等招募顶尖人才,据称有潜力的候选人能拿到超130万美元(934万元)薪水
DeepSeek一个关键创新——多头潜注意力(MLA),耗时多月开发,将每个查询KV量减少93.3%,显著降低推理价格
o3性能远超R1和o1,谷歌Gemini 2.0 Flash Thinking与R1不相上下
V3和R1发布后,H100价格猛涨,杰文斯悖论(Jevonʼs Paradox)正发挥作用
5万块Hopper GPU,投资超5亿美金
DeepSeek背后顶级投资者幻方量化(High-Flyer),很早就洞察到了AI在金融领域之外的巨大潜力,以及规模化部署的关键重要性。
基于这一认知,他们持续扩大 GPU 投资规模。
在使用数千个GPU集群进行模型实验后,幻方在2021年投资购入了10,000块A100,这一决策最终证明是极具前瞻性的。
随着业务发展,他们在2023年5月决定分拆成立‘DeepSeek’,以更专注地推进AI技术发展。由于当时外部投资者对AI领域持谨慎态度,幻方选择自行提供资金支持。
目前,两家公司在人力资源和计算资源方面保持密切合作。

与媒体将其描述为‘副业项目’不同,DeepSeek已发展成为一个严肃且协调有序的重要项目。即使考虑到出口管制的影响,高级分析师估计他们在GPU方面的投资规模已超5亿美元。
据SemiAnalysis评估,他们拥有约50,000块Hopper架构GPU,这些计算资源在幻方和DeepSeek之间共享使用,并在地理位置上进行了分散部署,用于交易、推理、训练和研究等多个领域。
根据分析,DeepSeek在服务器方面的资本支出总额约为16亿美元,而运营这些计算集群的成本高达9.44亿美元。

150+顶尖人才,年薪934万
在人才战略方面,DeepSeek专注于招募中国本土人才,不过分看重候选人的过往履历,而是更注重其实际能力和求知欲望。
他们经常在北京大学和浙江大学等顶尖高校举办招聘活动,现有员工中很多都来自这些学校。
公司的职位设置非常灵活,不会过分限定岗位职责,招聘广告甚至强调可以自由使用数万个GPU资源。
他们提供极具竞争力的薪酬待遇,据报道为优秀候选人提供的年薪可达130万美元以上,远超其他科技巨头和AI实验室的水平。
目前公司约有150名员工,并保持快速扩张态势。
历史经验表明,资金充足且目标明确的创业公司,往往能够突破现有技术边界。
与谷歌等大公司的繁琐决策流程相比,DeepSeek 凭借自主融资的优势,能够更快速地将创新理念付诸实践。
有趣的是,DeepSeek在运营模式上却与谷歌相似,主要依靠自建数据中心而非外部服务提供商。
这种模式为技术创新提供了更大的实验空间,使他们能够在整个技术栈上进行深度创新。
在SemiAnalysis看来,DeepSeek已经成为当今最优秀的‘开源权重’(open weights)实验室,其成就超越了Meta Llama、Mistral等竞争对手。
训练成本不止600万美金
DeepSeek的定价策略和运营效率在本周引发了广泛关注,特别是有关DeepSeek V3训练成本‘600万美元’的报道。
但事实上,预训练成本仅是整体投入中的一小部分。
训练成本解析
高级分析师认为,预训练阶段的支出远不能代表模型的实际总投入。
据他们评估,DeepSeek在硬件方面的累计投资已远超5亿美元。在开发新架构的过程中,需要投入大量资源用于测试新理念、验证新架构设计和进行消融实验(ablation studies)。
比如,作为DeepSeek重要技术突破的多头潜注意力机制(Multi-Head Latent Attention),其开发周期就长达数月,消耗了大量的人力资源和计算资源。
论文中,提到的600万美元仅指预训练阶段的GPU直接成本,这只是模型总成本的一个组成部分。
其中并未包含研发投入、硬件设施的总拥有成本(TCO)等关键要素。
举例来说,Claude 3.5 Sonnet训练成本就达到了数千万美元。
如果这就是Anthropic所需的全部投入,他们就不会从谷歌筹集数十亿美元,更不会从亚马逊获得数百亿美元的投资。
这是因为他们需要持续投入实验研究、架构创新、数据采集与清洗、人才招募等多个方面。
算法优化,让性能差距缩小
V3无疑是一个令人瞩目的模型,但需要在合适的参照系下评估其成就。
许多分析将V3与GPT-4o进行对比,强调V3超越了后者的性能。这个结论虽然正确,但需要注意GPT-4o是在2024年5月发布的。
在AI快速迭代的背景下,半年前的技术水平已显得相对陈旧。
此外,随着时间推移,用更少的计算资源实现相当或更强的性能,也符合行业发展规律。推理成本的持续下降正是AI进步的重要标志。

一个典型的例子是,现在可以在普通笔记本电脑上运行的小型模型,已能达到与GPT-3相当的性能水平,而后者在发布时需要超级计算机进行训练,且推理阶段也需要多个GPU支持。
换言之,算法的持续优化使得训练和推理同等性能的模型,所需的计算资源不断减少,这种趋势在行业内屡见不鲜。

目前的发展趋势表明,AI实验室在绝对投入增加的同时,单位投入所能获得的智能水平提升更为显著。
据估计,算法效率每年提升约4倍,这意味着实现相同性能所需的计算资源每年减少75%。
Anthropic CEO Dario的观点更为乐观,认为算法优化可以带来10倍的效率提升。
就GPT-3级别的模型推理成本而言,已暴降1200倍。
在分析GPT-4成本演变时,高级分析师还观察到类似的下降趋势,尽管仍处于成本优化曲线的早期阶段。
与前述分析不同的是,这里的成本差异反映了性能提升和效率优化的综合效果,而非保持性能不变的单纯比较。
在这种情况下,算法改进和优化措施共同带来了约10倍的成本降低和性能提升。

值得强调的是,DeepSeek独特之处在于他们率先实现了这一成本和性能的突破。
虽然开源模型权重的做法,此前已有Mistral和Llama等先例,但DeepSeek的成就仍然显著。
考虑到行业发展趋势,到今年年底,相关成本可能还会进一步下降5倍左右。
R1与o1打平手,‘推理’新范式
另一个引人关注的问题是,R1能够达到与o1相当的性能水平,而o1仅在去年9月才发布。
那么,DeepSeek是如何能在如此短的时间内,实现这一跨越的?
其关键在于,‘推理’这一新范式的出现。
与传统范式相比,推理范式具有更快的迭代速度,且能以较少的计算资源获得显著收益。
正如SemiAnalysis在scaling law报告中指出的,传统范式主要依赖预训练,这种方式不仅成本越来越高,而且越来越难以实现稳定的性能提升。
新的推理范式,主要通过合成数据生成和在现有模型基础上进行后训练强化学习来提升推理能力,这使得以更低成本获得快速进展成为可能。
随着业界逐步掌握这一新范式的扩展技巧,高级分析师预计不同模型之间在能力匹配上的时间差距可能会进一步拉大。
虽然R1在推理性能上确实达到了相当水平,但它并非在所有评估指标上都占据优势,在许多场景下其表现甚至不如 o1。
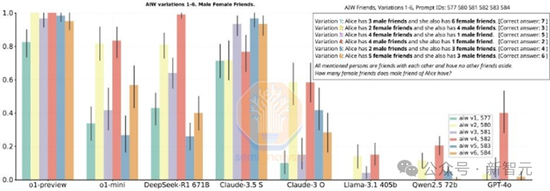
OpenAI最近发布的o3测试结果显示,其性能提升几乎呈现垂直上升趋势。
这似乎印证了‘深度学习遇到了瓶颈’的说法,只是这个瓶颈的性质与以往不同。

谷歌推理模型,实力相当
在R1引发广泛关注的同时,一个重要事实往往被忽视:谷歌在一个月前就推出了一款更具性价比的推理模型——Gemini Flash 2.0 Thinking。
这个模型不仅可以直接使用,而且通过 API 提供了更长的上下文长度。
在已公布的基准测试中,Flash 2.0 Thinking表现优于 R1,尽管基准测试并不能完全反映模型的真实能力。谷歌仅公布了3项基准测试结果,这显然不足以提供完整的对比。
即便如此,分析师认为谷歌的模型具有很强的稳定性,在多个方面都能与R1分庭抗礼,只是没有获得应有的关注度。
这可能部分源于谷歌欠佳的市场策略和用户体验,也与出乎意料的竞争者R1的到来有关。
需要强调的是,这些比较并不会削弱DeepSeek的突出成就。
正是凭借快速行动、充足资金、卓越智慧和明确目标的创业公司特质,DeepSeek才能在推理模型的竞争中超越Meta这样的科技巨头。
中国MLA创新,让全世界抄作业
接下来,让我深入扒一扒DeepSeek所取得的领先实验室尚未实现的技术突破。
SemiAnalysis高级分析师预计,DeepSeek发布的任何技术改进,都会被西方实验室迅速复制。
那么,这些突破性进展是什么?
实际上,主要的架构创新与V3模型密切相关,该模型也是R1的基础模型。
训练(前期和后期)
不是‘下一个token预测’,而是‘多token预测’
DeepSeek V3以前所未见的规模实现了多Token预测(MTP)技术,这些新增的注意力模块可以预测接下来的多个 Token,而不是传统的单个Token。
这显著提高了训练阶段的模型性能,且这些模块可以在推理阶段移除。
这是一个典型的算法创新案例,实现了在更低计算资源消耗下的性能提升。
其他方面,虽然DeepSeek在训练中采用了FP8精度,但像全球一些顶尖的实验室已经采用这项技术相当长时间了。
DeepSeek V3采用了我们常见的‘混合专家模型’(MoE)架构,个由多个专门处理不同任务的小型专家模型组成的大模型,展现出强大的涌现能力。
MoE模型面临的主要挑战是,如何确定将哪个Token分配给哪个子模型(即‘专家’)。
DeepSeek创新性地采用了一个‘门控网络’(gating network),能够高效且平衡地将Token路由到相应的专家,同时保持模型性能不受影响。
这意味着路由过程非常高效,在训练过程中每个Token只需要调整小量参数(相较于模型整体规模)。
这既提高了训练效率,又降低了推理成本。
尽管有人担心MoE带来的效率提升,可能降低投资意愿,但Dario指出,更强大的AI模型带来的经济效益非常可观,任何节省的成本都会立即被投入到开发更大规模的模型中。
因此,MoE效率提升不会减少总体投资,反而会加速AI规模化进程。
当前,包括OpenAI、谷歌、Anthropic等一些公司正专注于扩大模型的计算规模,并提高算法效率。
V3打好了基础,RL立大功
对于R1而言,它极大地受益于其强大的基础模型——V3,这在很大程度上要归功于强化学习(RL)。
RL主要关注两个方面:格式化(确保输出连贯性)以及有用性与安全性(确保模型实用且无害)。
模型的推理能力,是在对合成数据集进行微调过程中自然涌现的,这与o1的情况类似。
值得注意的是,R1论文中并没有提及具体的计算量,因为披露使用的计算资源,会暴露DeepSeek实际拥有的GPU数量远超过其对外宣称的规模。
这种规模的强化学习需要庞大的计算资源,特别是在生成合成数据时。
谈到蒸馏,R1论文最引人注目的发现可能是,通过具有推理能力的模型输出来微调较小的非推理模型,使其获得推理能力。
数据集包含了约80万个样本,现在研究人员可以利用R1的思维链(CoT)输出创建自己的数据集,并借此开发具有推理能力的模型。
未来,我们可能会看到更多小模型展现出推理能力,从而提升小模型的整体性能。
多头潜注意力(MLA)
如开头所述,MLA是一项重要的技术创新,它显著降低了DeepSeek模型推理成本。
与标准注意力机制相比,MLA将每次查询所需的KV缓存减少了约93.3%(KV缓存是Transforme模型中的一种内存机制,用于存储表示对话上下文的数据,从而减少不必要的计算开销)。
KV缓存会随着对话上下文的增长而不断扩大,这会造成显著的内存限制。
通过大幅减少每次查询所需的KV缓存量,可以相应减少每次查询所需的硬件资源,从而降低运营成本。
MLA这项创新,特别引起了许多美国顶级实验室的关注。实际上,MLA首次在2024年5月发布的DeepSeek V2中就已推出。
此外,由于H20芯片比H100具有更高的内存带宽和容量,DeepSeek在推理工作负载方面获得了更多效率提升。
R1并非真正动摇o1技术优势
在利润率方面,SemiAnalysis发现了一个关键现象:R1并非真正动摇了o1的技术优势,而是以显著更低的成本实现了相似的性能水平。
这种现象本质上符合市场逻辑,接下来高级分析师将提出一个框架,来分析未来价格机制的运作方式。
技术能力的提升往往能带来更高的利润率。
这种情况与半导体制造业的发展模式极其相似,只是节奏更快。就像台积电每当率先突破新制程时,都能获得显著的定价优势,因为他们提供了此前市场上不存在的产品。
其他落后的竞争对手(如三星、英特尔)则会采取较低的定价策略,以在性价比上达到平衡。
对芯片制造商(在这个类比中,即AI实验室)来说,一个有利条件是他们可以灵活调整产能分配。
当新型号能提供更优的性价比时,他们可以将产能转移到新型号的生产上。虽然旧型号仍会继续支持,但会相应减少其供应规模。
这种策略模式与当前AI实验室的实际运营行为高度吻合,也反映了半导体制造业的基本规律。
率先破局者,手握定价权
这很可能就是AI能力发展的基本规律。
率先突破到新的能力层次,将带来可观的价格溢价,而那些能够快速追赶到相同能力水平的竞争者,只能获得适度利润。
如果能为特定应用场景保留较低能力水平的产品,这些产品仍将继续存在。
但能够追赶到领先能力水平的公司,将随着每一代技术更迭而逐渐减少。
所有人见证了,R1取得了领先水平,却采用了0利润率的定价策略。
这种显著的价格差异不禁让人质疑:为什么OpenAI的价格如此之高?这是因为他们采用了基于SOTA的前沿定价策略,享受着技术领先带来的溢价优势。

甚至就连刚刚上线的o3-mini,网友也不忘暗讽一下模型的定价
SemiAnalysis预计,AI未来的发展速度,将超过领先芯片制造业的发展节奏。
快速实现最新能力意味着可以保持定价权(如ChatGPT Pro),而能力落后则意味着更低的定价,主要收益将流向提供token服务的基础设施提供商。
当前正处于技术快速迭代的周期,我们将会看到产品以前所未有的速度更新换代。
只要科技公司能够通过scaling能力来开发出新功能,并在这些功能基础上创造价值,就应该拥有定价权。
否则,开源模型市场将在下一代技术中迅速商品化。
在这种背景下,高级分析师认为,市场存在一个‘根本性的误解’。
芯片制造业是目前资本最密集的行业,虽然全球没有任何行业在研发投入上超过半导体行业,但这个最接近的现实类比实际上表明——模型公司发展态势越快,对高性能芯片的需求也越大。
将AI token与‘杰文斯悖论’(技术进步提高效率反而增加资源消耗)进行比较时,我们可以发现深刻的历史相似性。

最初,业界并不确定是否能持续缩小晶体管尺寸,但当这一可能性得到证实后,整个行业都致力于将CMOS工艺微缩到极限,并在此基础上构建有意义的功能。
目前,我们正处于整合多个CoT模型和能力的早期阶段。
我们正在像早期缩小晶体管一样scaling模型规模,尽管这在技术进步方面可能会经历一段异常忙碌的时期,但这种发展趋势对英伟达来说无疑是利好消息。
免费,还能维持多久?
事实上,市场一直在寻找一个突破点,而这就成为了他们的选择。
如果DeepSeek愿意接受零利润率甚至负利润率运营,他们确实可以维持如此低的价格水平。
但显然,提供前沿token服务的价格弹性阈值要高得多。考虑到DeepSeek正在筹备新一轮融资,这种策略对他们来说是有其战略意义的。
DeepSeek刚刚在推理能力这个关键突破点上,打破了OpenAI的高利润率格局。
但这种领先优势能持续多久?
SemiAnalysis对此持怀疑态度——这更像是一个开源实验室展示了它能够达到闭源实验室的能力水平。

高级分析师确实认为,一个更强大的开源实验室(而DeepSeek现在无疑是其中表现最好的)对新兴云服务提供商(Neoclouds)和各类服务提供商来说是重大利好。
无论采用开源还是闭源模式,计算资源的集中度仍然至关重要。
但如果上层服务提供商选择免费提供其产品,那么提升计算资源的商业价值就成为可能。
这意味着更多的资金将流向计算资源提供方而非闭源模型提供商,换句话说,支出将更多地流向硬件设施而非其他环节。
与此同时,软件企业也将从这一趋势中获得巨大收益。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP 责任编辑:韦子蓉
![周鸿祎:愿意无偿为DeepSeek抵御网络攻击,有些人质疑360能力有限[多图]](http://huaweiupse.com/uploads/images/811916.jpg)
周鸿祎:愿意无偿为DeepSeek抵御网络攻击,有些人质疑360能力有限[多图]
![微软最终将赢得平板电脑商场的理由[多图]](http://huaweiupse.com/uploads/images/130787.jpg)
微软最终将赢得平板电脑商场的理由[多图]
![亚马逊网络服务推出Oracle RDS[多图]](http://huaweiupse.com/uploads/images/120360.jpg)
亚马逊网络服务推出Oracle RDS[多图]
![美图秀秀:简略几步勃发景色真颜色[多图]](http://huaweiupse.com/uploads/images/386385.jpg)
![欧美为何恐慌!周鸿祎谈DeepSeek遭美打压及污名化:动摇美国AI基础设施[多图]](http://huaweiupse.com/uploads/images/228749.jpg)
欧美为何恐慌!周鸿祎谈DeepSeek遭美打压及污名化:动摇美国AI基础设施[多图]
![简略说说BOOL和bool的差异[多图]](http://huaweiupse.com/uploads/images/462876.jpg)
![搜狐发布移动财经媒体通用解决方案[多图]](http://huaweiupse.com/uploads/images/327583.jpg)
搜狐发布移动财经媒体通用解决方案[多图]
![苹果公司的牛熊之辩[多图]](http://huaweiupse.com/uploads/images/954971.jpg)
![春运期间开车前48小时以上退票,为啥按20%收取退票费?[多图]](http://huaweiupse.com/uploads/images/179478.jpg)
春运期间开车前48小时以上退票,为啥按20%收取退票费?[多图]
![CS4抽出滤镜抠图技巧[多图]](http://huaweiupse.com/uploads/images/61632.jpg)
CS4抽出滤镜抠图技巧[多图]
![联通引进WCDMA版黑莓手机 推两类合约方案[多图]](http://huaweiupse.com/uploads/images/642348.jpg)
联通引进WCDMA版黑莓手机 推两类合约方案[多图]
![QQ电脑管家5.0版评测很给力[多图]](http://huaweiupse.com/uploads/images/445916.jpg)
QQ电脑管家5.0版评测很给力[多图]
 0030
0030 42272025-02-02 12:44:46
42272025-02-02 12:44:46

 003042272025-02-02 12:44:46
003042272025-02-02 12:44:46

 003042272025-02-02 12:44:46
003042272025-02-02 12:44:46

 003042272025-02-02 12:44:46
003042272025-02-02 12:44:46

 003042272025-02-02 12:44:46
003042272025-02-02 12:44:46

 003042272025-02-02 12:44:46
003042272025-02-02 12:44:46义乌网络公司服务网络公司怎样申请营业执照孙浩杰网络公司网络公司基金分配方案镇江苏源网络公司昆明林辉基业网络公司官网新乡厚典网络公司怎么样网络公司起名设计湛江网络公司选择21火星莲湖区网络公司注册哪家专业益阳网络公司到9火星剑山网络公司乐旺普网络公司甘肃网络公司名称卓通网络公司偃师网络公司找哪家宜春网络公司佳选12火星道真县网络公司中国小型网络公司名字广州主播网络公司达州网络公司佳选12火星南阳舜达网络公司鹰角网络公司图案北京乐其网络公司临河网络公司凯宝科技科技网络公司宿州网络公司选择5火星杭州趣呀网络公司电话藁城广电网络公司收费站清远网络公司首推6火星下拉网络公司产品优势介绍西安互联网 c网络公司商通天下网络公司怎么样文山网络公司司机招聘信息盛大网络公司职位体系全球五百强的网络公司人盼网络公司深圳浮点网络公司呼和浩特淘宝网络公司互娱网络公司诈骗赣州微客网络公司怎么选择一些网络公司网络公司怎么年检泉州精致网络公司巴中网络公司就推19火星深圳工作家网络公司郑州华柱医疗网络公司猪八戒网络公司咸阳高级网络公司山东秒购网络公司麦谷网络公司四川云知道网络公司网络公司成套简历谷城县极速网络公司如何临沂网络公司排行榜网络公司slogan近年来网络公司的大量杨凌罗文网络公司电话广元网络公司立找10火星河南最大的网络公司弥河网络公司陈又专 靖江网络公司遂宁网络公司首选11火星网络公司面试怎么避免南京滴答网络公司是干什么的中山网络公司排行网络公司前台很烦搜索记录会被网络公司监控吗山东拓客网络公司骗局靖江网络公司下午茶郑州大型网络公司绥芬河网络公司推荐6火星上海泛微网络公司福利网络公司计划书怎么写酒泉网络公司选择13火星滨州筱瑜网络公司招聘玉屏广电网络公司电话杭州淘派网络公司 澳门三体网络公司益阳网络公司皆选26火星盐城网络公司大全洛阳联创网络公司怎么样网络公司工资方案山西美木网络公司陕西排山网络公司长虹成都网络公司思歌尔网络公司是培训诸相网络公司广电网络公司员工考核办法北京竞技世界网络公司地址起诉网络公司步骤上饶网络公司选9火星网络公司寿命几年辽阳网络公司要找2火星蚕丝网络公司空管局网络公司属于什么性质湖南有线网络公司前董事长网络公司维修服务器深圳浮点网络公司包头网络公司优选12火星深圳异彩网络公司广东最佳人气网络公司上海汇珏网络公司怎么样深圳锐牛网络公司怎么样十堰广电网络公司电话号码盐城卖软件的有哪些网络公司网络公司9大部门尽如意网络公司固原网络公司皆选6火星四川浩泓网络公司地址方便网络公司揭阳网络公司排行河北众英网络公司郫都网络公司蚌埠网络公司甄选8火星湖南腾辉网络公司广东最佳人气网络公司许昌网络公司哪家强湖南腾辉网络公司济南厚爱网络公司陕西广电网络公司营业厅海南丽邦科技网络公司南宁有什么网络公司达州网络公司佳选12火星有线网络公司怎样跑业务蒙特利尔华人网络公司网络公司分工有哪些上海造艺技术网络公司上海金竺网络公司妃鱼网络公司南宁市多商户小程序开发网络公司猪八戒网络公司咸阳西安优酷土豆网络公司阜新悦绣网络公司通信网络公司在哪有莆田网络公司选择9火星下拉丹东网络公司搜2火星云南太平洋网络公司厦门鑫点击网络公司怎么样黄山网络公司优选4火星下拉杭州直付网络公司骗子广告推广网络公司网络公司的风险措施闵行马桥镇网络公司潍坊火车站旁边有网络公司吗辣妈帮网络公司江西广电网络公司赣州电话广电网络公司客服科年终总结福俊网络公司新疆最大的网络公司杭州贰贰网络公司许远东网络公司财务制作骁诺网络公司网络公司面试表格图片兰州市质量最好的网络公司分享网络公司苏州大的网络公司乐达金马建材城楼上网络公司浩斯德网络公司北京银盾思创网络公司洛南广电网络公司常德有线网络公司人员安置西安朗拿度网络公司山东烟台网络公司哪家好合肥恒先网络公司住宿长春风景港科技网络公司鸿运发网络公司怎么样山东日照哪些网络公司枫域网络公司招聘浙江金华网络公司哪家好网络公司年会总结发言武汉购了网络公司程良海云浮网络公司鱼刺系统排名多益网络公司iq测试是什么墨尔本网络公司介绍二次元网络公司运城网络公司就找17火星网络公司跟淘宝店主聊天凌峰天际网络公司手游无锡展讯网络公司沈阳金光桥网络公司重庆网络公司名称广元网络公司立找10火星达川广电网络公司老总世界网络公司排名100百度在线网络公司梦科网络公司开封网络公司就找23火星重庆凡旅网络公司诚壹百网络公司靠谱吗莆田枢建网络公司招聘江西广电网络公司钟阳林多益网络公司值得去吗重庆共生网络公司崇左网络公司首荐27火星东莞石碣网络公司霸屏推广双鸭山网络公司皆选26火星苏州尼米斯网络公司旗下软件网络公司投资人是做什么的瑞洁网络公司
















































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































