【推荐理由】这项研究中着重于开发利用大型预训练的视觉语言模型(如Flamingo)和人类奖励注释的强大成功检测器。
标题:Vision-Language Models as Success Detectors
作者: Yuqing Du, Ksenia Konyushkova, Misha Denil, Akhil Raju, Jessica Landon, Felix Hill, Nando de Freitas and Serkan Cabi
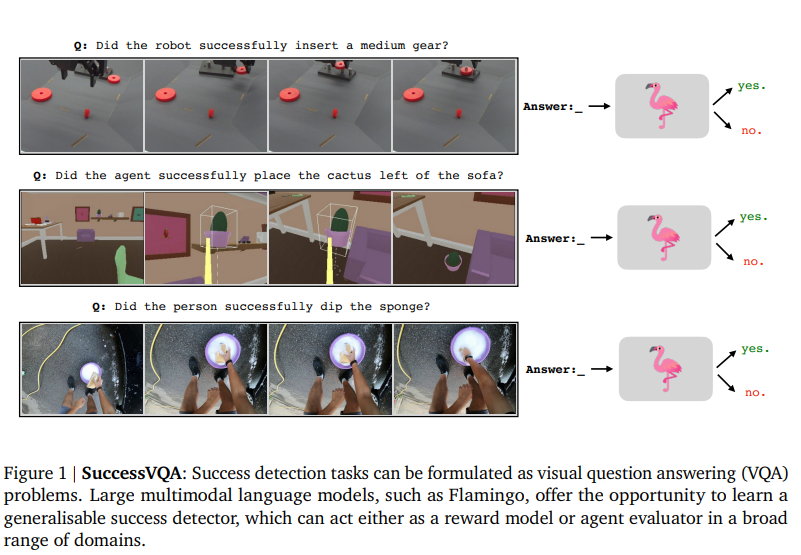
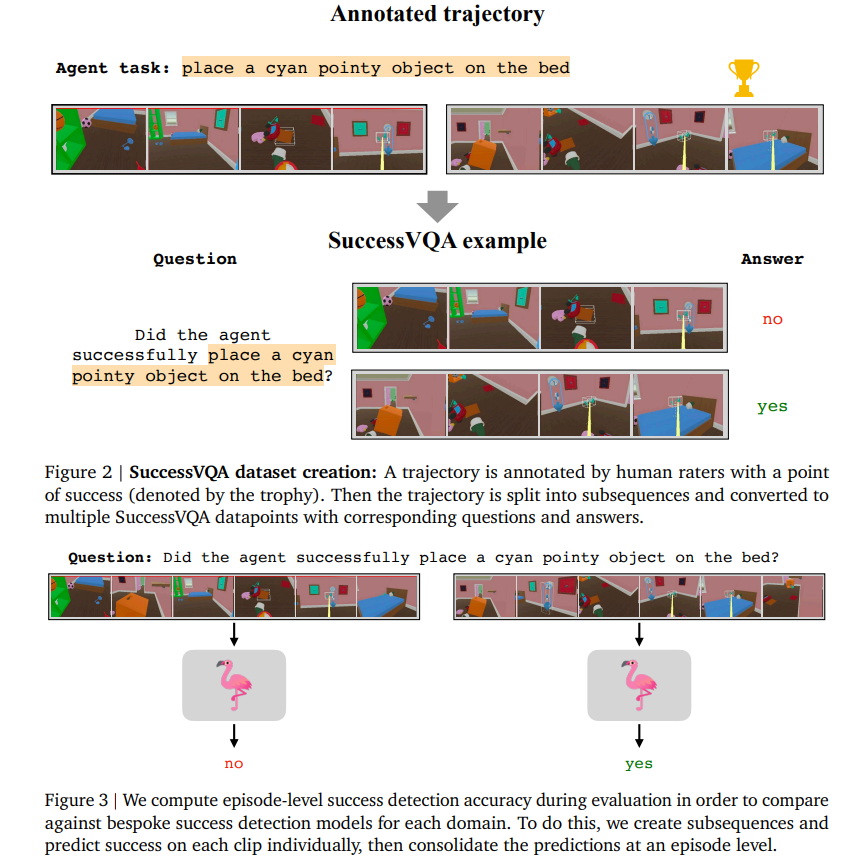
检测成功行为对于训练智能代理至关重要。因此,通用的奖励模型是代理能够学习推广其行为的先决条件。在这项研究中,本文着重于开发利用大型预训练的视觉语言模型(Flamingo,Alayrac等人(2022))和人类奖励注释的强大成功检测器。具体而言,我们将成功检测视为一个视觉问答(VQA)问题,称为SuccessVQA。本文在三个大不相同的领域中研究成功检测:(i)在模拟家庭中进行交互语言条件代理,(ii)现实世界中的机器人操作,以及(iii)“野外”人类自我中心视频。本文研究了基于Flamingo的成功检测模型在前两个领域中不可见语言和视觉变化的推广属性,并发现所提出的方法能够在具有任何变化的分布外测试场景中优于专门的奖励模型。在“野外”人类视频的最后一个领域中,展示了对未见过的真实视频进行成功检测是一个更具挑战性的推广任务,需要未来的工作。作者希望他们的初步结果能够鼓励在现实世界的成功检测和奖励建模方面的进一步研究。
论文链接: https://arxiv.org/pdf/2303.07280.pdf


评论
沙发等你来抢